
DBMS 2022 NEP Solved Question Paper (Database Management System)
Click here to Download DBMS NEP 2022 Question Paper.
Section - A
Answer any Ten of the following. (10×2=20)
1. What is DBMS?
A database management system (DBMS) is a software application that helps users create, read, update, and delete data in a database. It provides an interface between the user and the database, and manages the storage and retrieval of data.
2. Define data independency.
Data independence is the property of a database management system (DBMS) that allows changes to be made to the database structure without affecting the application programs that use the database.
3. What is data language?
A data language is a specialized programming language used to define, manipulate, and query data in a database management system (DBMS).
4. Define Entity.
An entity in a database management system (DBMS) is a real-world object or concept that is represented in the database. Entities can be people, places, things, or events.
Entities are typically represented in a database by tables.
5. Define Attribute with example.
An attribute in a database management system (DBMS) is a property or characteristic of an entity. Entities are real-world objects or concepts that are represented in the database. For example, in a customer database, entities might include customers, orders, and products.
6. Write about weak entity.
A weak entity in a database management system (DBMS) is an entity that cannot be uniquely identified by its own attributes. It must rely on the attributes of another entity, called the owner or dominant entity, to be uniquely identified. Weak entities are typically represented with a double-rectangle box in an entity-relationship diagram (ERD).
7. Define Domain constraints with example.
Domain constraints in a database management system (DBMS) are rules that define the set of valid values for an attribute. They are used to ensure that the data in the database is accurate and consistent.
- data type constraints
- Range constraints
- Uniqueness constraints
- Check constraints
8. What is Relational Algebra?
Relational algebra is a procedural query language that is used to define and manipulate data in relational databases. It is a theoretical foundation for relational databases and Structured Query Language (SQL).
9. Define Normalization.
Normalization is a process of organizing data in a database to minimize redundancy and improve data integrity.This helps to ensure that the data is accurate and consistent, and that it can be easily updated and deleted.
10. Define First normal form.
a relation is in 1NF if all of its attributes are atomic, meaning that they cannot be further subdivided into smaller units. This means that each attribute in a 1NF relation must be a single value, such as a name, address, or date.
11. What is dead lock?
A deadlock is a situation in which two or more processes are waiting for each other to finish, and neither of them can finish. This can happen when each process has locked a resource that the other process needs.
12. Expand ACID
ACID is an acronym for Atomicity, Consistency, Isolation, and Durability.
Section - B
Answer any Four of the fallowing (4x5=20)
13. Explain three schema architecture of database system with neat diagram.
The three-schema architecture of a database system is a logical design that separates the database into three levels: external, conceptual, and internal.
External schema: The external schema is the view of the database that is seen by individual users and applications. It is also known as the user schema or the application schema. The external schema defines the logical structure of the data that is available to each user or application.
Conceptual schema: The conceptual schema is the overall logical view of the database. It describes the entities, attributes, and relationships in the database. The conceptual schema is independent of any specific physical implementation of the database.
Internal schema: The internal schema is the physical implementation of the database. It describes how the data is stored and accessed in the database. The internal schema is specific to the database management system (DBMS) that is being used.
This separation of concerns provides a number of benefits, including:
- Data independence
- Security
- Performance
The three-schema architecture allows the retail company to change the physical implementation of the customer database without affecting the users or applications that use the database. For example, the company could change the way that the data is stored in the database without having to change the external schema or the conceptual schema. This makes the database more flexible and easier to maintain.

14. Discuss Attributes with its types
Attributes in a database management system (DBMS) are properties or characteristics of an entity. Entities are real-world objects or concepts that are represented in the database. For example, in a customer database, entities might include customers, orders, and products. Attributes are the columns in the database tables that describe the entities.
There are different types of attributes in a DBMS, including:
- Simple attributes: Simple attributes are attributes that cannot be further subdivided. For example, the customer ID attribute in a customer database is a simple attribute.
- Composite attributes: Composite attributes are attributes that can be further subdivided into other attributes. For example, the address attribute in a customer database is a composite attribute that can be subdivided into street address, city, state, and zip code.
- Single-valued attributes: Single-valued attributes can only have one value for each entity. For example, the customer ID attribute in a customer database is a single-valued attribute.
- Multi-valued attributes: Multi-valued attributes can have multiple values for each entity. For example, a customer might have multiple phone numbers, so the phone number attribute in a customer database would be a multi-valued attribute.
- Stored attributes: Stored attributes are attributes that are physically stored in the database. For example, the customer name attribute in a customer database is a stored attribute.
- Derived attributes: Derived attributes are attributes that are calculated from other attributes. For example, the total order amount attribute in an order database is a derived attribute that is calculated by multiplying the order quantity by the product price.
- Key attributes: Key attributes are attributes that are used to identify entities uniquely. For example, the customer ID attribute in a customer database is a key attribute.

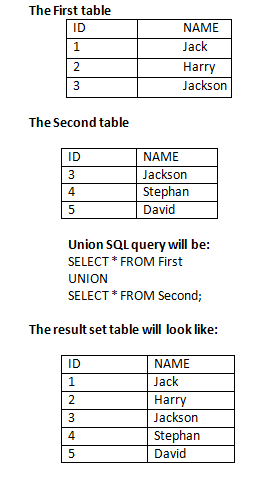
15. Explain UNION, INTERSECTION and MINUS operations in Relation Model.
1.Union
The SQL Union operation is used to combine the result of two or more SQL SELECT queries.
In the union operation, all the number of datatype and columns must be same in both the tables on which UNION operation is being applied.
The union operation eliminates the duplicate rows from its resultset.
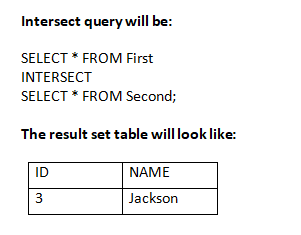
2.Intersection
It is used to combine two SELECT statements. The Intersect operation returns the common rows from both the SELECT statements.
In the Intersect operation, the number of datatype and columns must be the same.
It has no duplicates and it arranges the data in ascending order by default.
Using the above First and Second table.
3.Minus
It combines the result of two SELECT statements. Minus operator is used to display the rows which are present in the first query but absent in the second query.
It has no duplicates and data arranged in ascending order by default.
Using the above First and Second table.

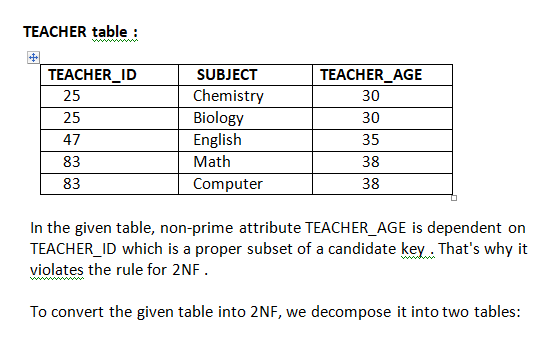
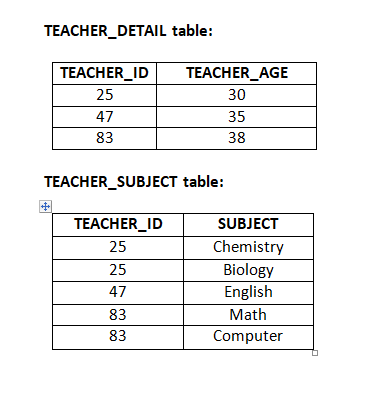
16. Explain second normal form with suitable example.
Second Normal Form (2NF)
In the 2NF, relational must be in 1NF.
In the second normal form, all non-key attributes are fully functional dependent on the primary key
Example:
Let’s assume, a school can store the data of teachers and the subjects they teach. In a school, a teacher can teach more than one subject.
17. Write about types of Failure in transaction processing.
To find that where the problem has occurred, we generalize a failure into the following categories:
1. Transaction failure
2. System crash
3. Disk failure
1. Transaction failure
The transaction failure occurs when it fails to execute or when it reaches a point from where it can’t go any further. If a few transaction or process is hurt, then this is called as transaction failure.
Reasons for a transaction failure could be –
1. Logical errors: If a transaction cannot complete due to some code error or an internal error condition, then the logical error occurs.
2. Syntax error: It occurs where the DBMS itself terminates an active transaction because the database system is not able to execute it. For example, The system aborts an active transaction, in case of deadlock or resource unavailability.
2. System Crash
System failure can occur due to power failure or other hardware or software failure. Example: Operating system error.
Fail-stop assumption: In the system crash, non-volatile storage is assumed not to be corrupted.
3. Disk Failure
It occurs where hard-disk drives or storage drives used to fail frequently. It was a common problem in the early days of technology evolution.
Disk failure occurs due to the formation of bad sectors, disk head crash, and unreachability to the disk or any other failure, which destroy all or part of disk storage.
Section - C
Answer any Two of the following. (2×10=20)
18. Explain people associated with database system.
Many persons are involved in the design, use, and maintenance of a large database with a few hundred users. Here we will consider people who may be called “Actors on the Scene”, whose jobs involve the day-to-day use of a large database.
1.Database Administrators: Administrating the primary (database) and secondary (DBMS and related software) is the responsibility of the database administrator (DBA). The DBA is responsible for authorizing access to the database, coordinating and monitoring its use, and acquiring software and hardware resources as needed.
2.Database Designers: Database Designers are responsible for identifying the data to be stored in the database and for choosing appropriate structures to represent and store this data. Database designers typically interact with each potential group and user and develop a view of the database that meets the data and processing requirements of these groups.
- End Users: End users are the people whose jobs require access to the database for querying, updating, and generating reports; the database primarily exists for their use. There are several categories of end users:
- Casual end user: Occasionally access the database, but they may need different information each time. They are typically middle-or high-level managers or other occasional browsers.
- Naive or Parametric end user: Their main job function revolves around constantly querying and updating the database, using standard types of queries and updates that have been carefully programmed and tested. Bank tellers, Reservation Clerks for airlines, hotels, etc are the example of Naive end users.
- Sophisticated end users: Sophisticated end users include engineers, scientists, business analysts, and others who thoroughly familiarize themselves with the facilities of the DBMS so as to implement their applications to meet their complex requirements.
- Stand-alone users: They maintain the personal databases by using ready-made program packages that provide an easy-to-use menu or graphics-based interfaces.
3.Software Engineers: System analysts determines the requirements of end users, especially naive and parametric end users, and develop specifications for canned transactions that meet these requirements.Application programmers implement these specifications as programs; then they test, debug, document, and maintain these canned transactions. Such analysts and programmers are called Software Engineers.
19.
a. Discuss cardinality Ratio for Relationship type.
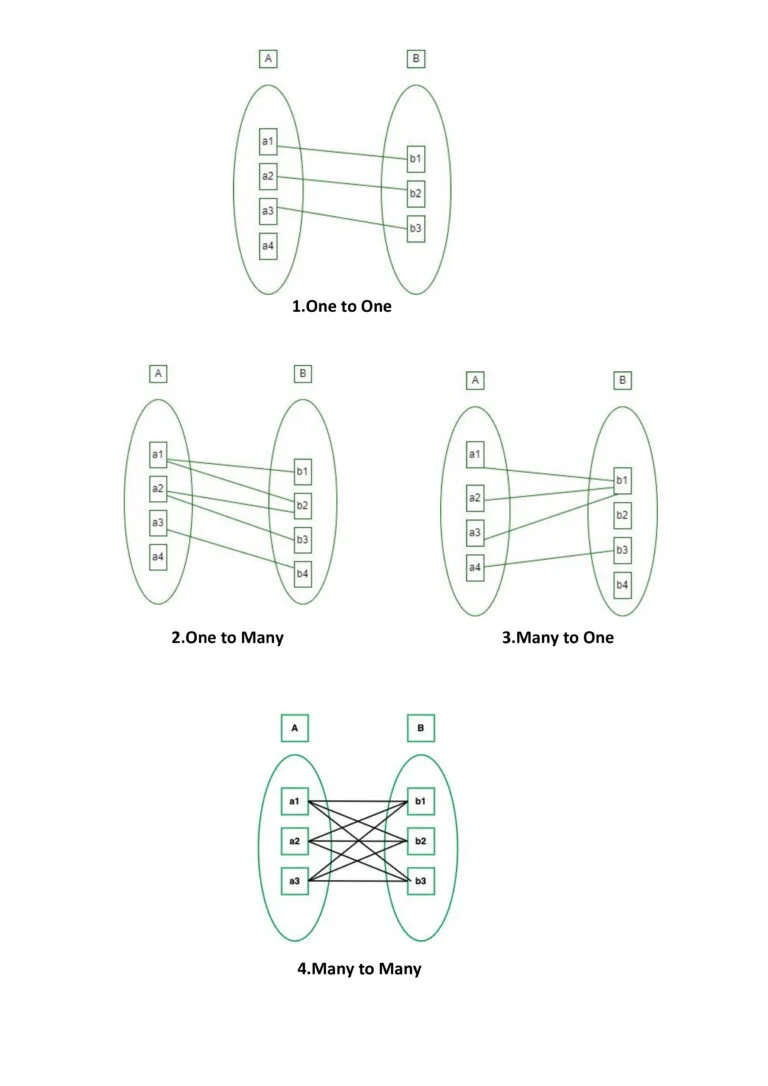
There are four types of Cardinality Mapping in Database Management Systems:
1. One to one
2. Many to one
3. One to many
4. Many to many
1. One-to-one: In this type of cardinality mapping, an entity in A is connected to at most one entity in B. Or we can say that a unit or item in B is connected to at most one unit or item in A.
Many to One Cardinality:
2. One-to-many: In this type of cardinality mapping, an entity in A is associated with any number of entities in B. Or we can say that one unit or item in B can be connected to at most one unit or item in A.
3. Many-to-one: In this type of cardinality mapping, an entity in A is connected to at most one entity in B. Or we can say a unit or item in B can be associated with any number (zero or more) of entities or items in A.
4. Many-to-many: In this type of cardinality mapping, an entity in A is associated with any number of entities in B, and an entity in B is associated with any number of entities in A.
b. Write PL/SQL program to find sum of three numbers.
DECLARE
a NUMBER := 10;
b NUMBER := 20;
c NUMBER := 30;
sum NUMBER;
BEGIN
sum := a + b + c;
DBMS_OUTPUT.PUT_LINE(‘The sum of the three numbers is ‘ || sum);
END;
/
20.
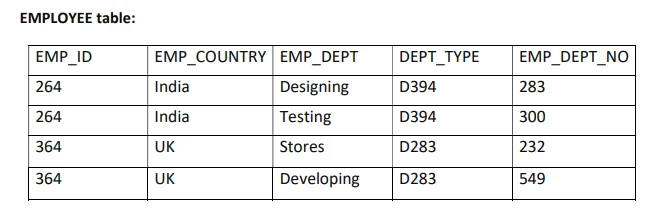
a. Explain Boyce-codd normal form.
Boyce Codd normal form (BCNF)
- BCNF is the advance version of 3NF. It is stricter than 3NF.
- A table is in BCNF if every functional dependency X → Y, X is the super key of the table.
- For BCNF, the table should be in 3NF, and for every FD, LHS is super key.
Example: Let’s assume there is a company where employees work in more than one department.

b. Explain lost update problem.
A lost update problem occurs due to the update of the same record by two different transactions at the same time.
In simple words, when two transactions are updating the same record at the same time in a DBMS then a lost update problem occurs. The first transaction updates a record and the second transaction updates the same record again, which nullifies the update of the first transaction. As the update by the first transaction is lost this concurrency problem is known as the lost update problem.
Lost update problem is a write-write conflict.
Now, let’s see how one transaction nullifies the updated.
lost-update-problem-example
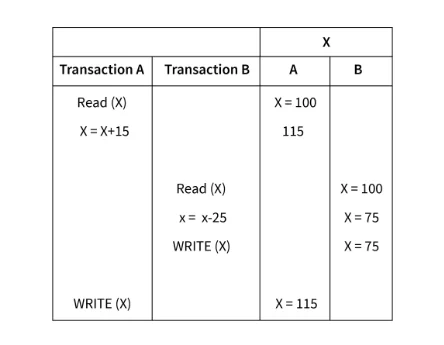
Let’s understand the transactions being performed in the above image:
X = 100
Transaction A is reading record X = 100 and adding 15 to X, but this transaction is not yet reflected on DB. As write operation is not performed. (Result temp_X = 115)
Transaction B also reads X but here it is not getting updated value after transaction A. Hence, X = 100. And subtracting 25 from X. And write commit operation is performed on X. Hence, X = 75
Write commit operation for transaction A is performed. Hence X = 115
Here, the actual results of transactions A and B should be: X = 100, X after transaction A: X = 115, Transaction B begins: X = 115, X after transaction B: X = 95.
After performing transactions A and B value of X should have been X = 95.
But due to a lost update problem the result of Transaction B is lost and the final result is X = 115.
its helpful for examinetion